
Videos
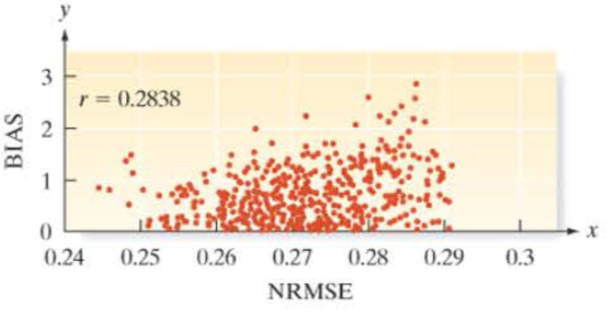
Evaluation of an imputation method for missing data. When analyzing big data (large data sets with many variables), business researchers often encounter the problem of missing data (e.g., non-response). Typically, an imputation method will be used to substitute in reasonable values (e.g., the mean of the variable) for the missing data. An imputation method that uses “nearest neighbors” as substitutes for the missing data was evaluated in Data & Knowledge Engineering (March 2013). Two quantitative assessment measures of the imputation algorithm are normalized root mean square error (NRMSE) and classification bias. The researchers applied the imputation method to a sample of 3,600 data sets with missing values and determined the NRMSE and classification bias for each data set. The
a. Conduct a test to determine if the true population correlation coefficient relating NRMSE and bias is positive. Interpret this result practically.
b. A scatterplot for the data (extracted from the journal article) is shown below. Based on the graph, would you recommend using NRMSE as a linear predictor of bias? Explain why your answer does not contradict the result in part a.
Want to see the full answer?
Check out a sample textbook solution
Chapter 11 Solutions
Statistics for Business and Economics (13th Edition)


 Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill
Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt
Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL
Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL